





Back in the days….
On July 20th, 1969, mankind made a giant leap – we landed on the moon. Half a billion people gathered in front of their TVs to witness Neil Armstrong perform the first walk on the surface of the silver globe. “That’s one small step for man, one giant leap for mankind.”
This was possible thanks to the efforts of many scientists, engineers—and computers. One of the indispensable devices for the Apollo mission was AGC – the Apollo Guidance Computer, which allowed the astronauts to type in basic commands (nouns and verbs) that controlled their spaceship. AGC had 64Kbytes of memory and operated at 0.043MHz. Back on Earth, engineers used computers that were the most complex machines at the time, with the most complex software ever created. Bigger than cars, their total memory capacity could be measured in megabytes. Compare that to today’s hardware, or your own home pc for that matter…
In theory, the progress that has been made in processing and gear means that science should rapidly grow within nanoseconds—and in theory, it does. We know more, we move faster, we constantly transcend limits. But “the more you know, the more you know you don’t know.” More precisely, the more precise research becomes, the more data it has to “digest” to provide useful results and the more work power it needs to do so.

Proteins
One field that requires a lot of manpower for data analysis is biology. Take proteins: recognized as biological molecules in the eighteenth century, they were first described and named in 1838. ‘Protein’ comes from the Greek proteios, meaning “primary”, reflecting their significance. Further research led to further discoveries – proteins are everywhere in your body and serve a plethora of functions: to guard you, provide energy, build hormones and muscles, regulate your genes and allow you to move. They have a hand in almost everything that happens in your body. Not surprisingly, they are also very complex when it comes to construction.
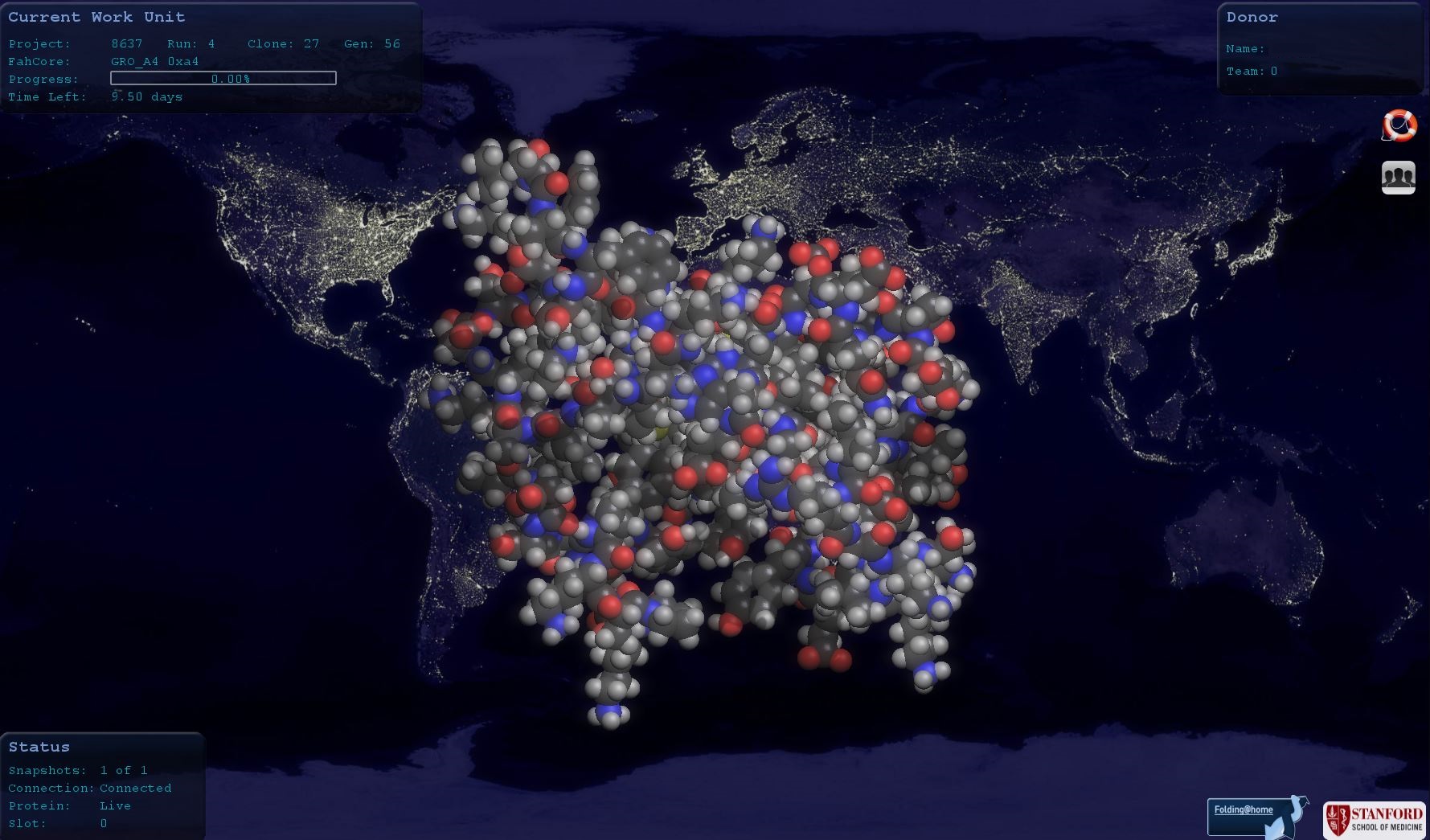
Before proteins can do anything, they need to “fold”, or assemble themselves. And they don’t fold just once. In fact, they spend around 96% of their folding time in various intermediate forms. They can also misfold, which can cause numerous and severe illnesses, among them Alzheimer’s, BSE, ALS, AIDS, Parkinson’s, Huntington’s disease and many forms of cancer. Understanding why and how proteins misfold can be a first step in combating the effects of the phenomenon and leads to drugs and therapies being designed to combat those illnesses. To make it simple: projects focused on folding take the intermediate forms of proteins and project further changes, discovering new forms of the proteins and directions of folding. Highly detailed, a complete model can contain thousands of sample states and the transitions between them. Such a model as an in vitro (“in the glass”) experiment helps scientists to not only discover “what” happens, but also “why” and “when”, especially when accompanied by experiments in vivo (“within the living”).
[email protected]
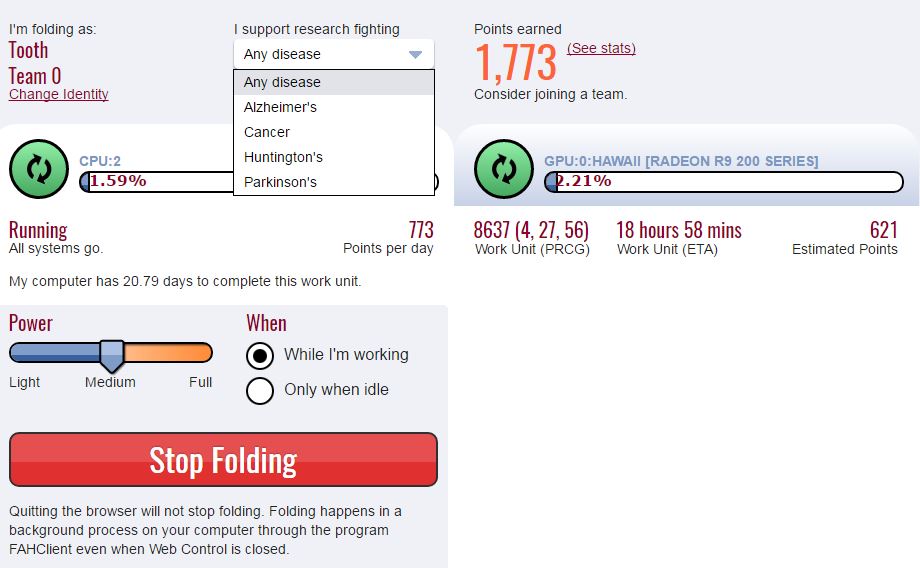
Among the largest and most important distributed computing projects, [email protected] was created and is maintained by Stanford University. Like other such projects, it uses your CPU for research, in this case to fold proteins and to design drugs used as cures. Strength here lies in numbers. Instead of engaging one huge, insanely expensive machine that would take years to perform the folding, researchers rely on multiple small bits of data processed by home computers. The army of home PCs can do more than any supercomputer. You install a small application and when you launch it, you get a “task”. Your computer solves it then sends it back to the Project. It’s as simple as that. You don’t even need the latest gear to play a role in the process – any machine will do, even your Android phone can be helpful. The process won’t drain your machine’s resources, and you may not even notice the software is running.

But isn’t this going to be a burden for your PC? Yes and no. The software installed offers you multiple ways of protecting your machine – from how much PC power you wish to dedicate to the task to even setting it to activate only when your computer is idle or to limiting the number of cores available. You can also choose which illness you want to research and which method you prefer – [email protected] is not the only distributed computing project focused on proteins. There’s [email protected], CureCancer, [email protected], [email protected], ANPAKU, [email protected], [email protected] and many more. All those projects are non-profit and work for science, in this case proteins.

Here are two cases that show just how multifarious the world of protein research is and how various projects may complement one another. [email protected], created at the University of Washington and Howard Hughes Medical Institute, uses energy functions to find the lowest or most stable state of proteins. It was set up to predict protein-protein docking and their structures. The other, [email protected], uses physics to determine how proteins fold. So, in simple words: Rosetta can tell you what a protein will look like while [email protected] will tell you how it changes in an organism.

Launched way back in 2000, [email protected]’s potential was quickly recognized in the scientific world. By 2005 the project had published papers on antibiotics, Alzheimer’s Disease, Osteogenesis, Parkinson’s Disease and cancer. Research on Chagas, malaria, Huntington and diabetes followed. The length of proteins studied increased significantly while the time needed to fully fold a protein decreased. In September 2007, the Guinness World Records recognized [email protected] as the most powerful distributed computing network. As of June 2017, 1,883,632 people have non-anonymously contributed to the project. Until now, 139 scientific papers have been published based on projects folded by people from around the globe. Many developers like Nvidia and AMD (as ATI) joined the project, adjusting their gear and releasing updates for their drivers to better work with folding. And that’s just data for [email protected]
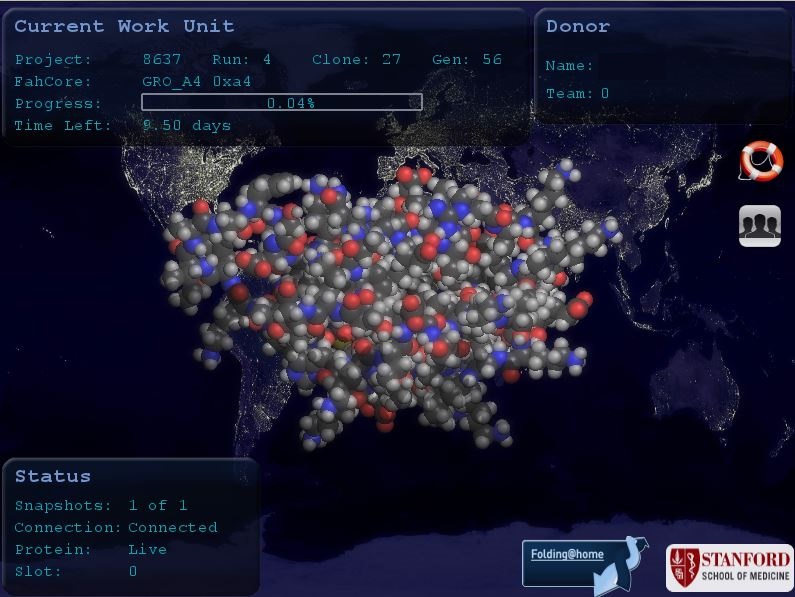
There is also a community aspect involved in folding. Not only can you help find a cure, but also compete with others to see who folds the most. When you finish a project, you get points for it. Of course, the formula is a bit more complicated, but important factors in the equation are the time your machine needs to process the assignment and the base score established on the benchmark machine. Each work unit also has a certain deadline set, the only limitation, gearwise, which older machines may struggle with. You can be a lone warrior fighting for a good cause or join a team already working on a project. You can even invite your friends and create your own team. Your PCs progress will go towards your team’s total score [http://fah-web.stanford.edu/cgi-bin/main.py?qtype=userstats] as well as your own individual progress [http://fah-web.stanford.edu/cgi-bin/main.py?qtype=userstats] and you can view those stats at any time.
Getting involved is really simple:
Step 1. Download the software (f.ex. [email protected] [https://folding.stanford.edu/start-folding/] or [email protected] [http://boinc.berkeley.edu/download.php])
Step 2. Run the installation. Launch the software
Step 3. Follow the instructions to start a project.
Yep, that’s all you need to do. Once your software is ready, the project you’ve joined will send a folding task straight to your pc. You can also start an account and participate under your nickname (on a team or solo) or you can help anonymously. Once your computer solves an assignment, it will receive another. You choose when it starts and for how long it goes. Of course, the faster your machine is, the faster it will process the tasks given, but you can start the software on pretty much any hardware and system.
Happy folding!
Useful links:
http://folding.stanford.edu/
http://boinc.bakerlab.org/rosetta/
http://www.hyper.net/dc-howto.html
http://boinc.bakerlab.org/rosetta/forum_thread.php?id=1790
http://boinc.bakerlab.org/rosetta/forum_thread.php?id=1074










